想要尝试StableDiffusion绘画的可以看看,这是在本地(本文以Linux为例)部署ComfyUI的流程。
一、克隆项目
项目连接:ComfyUI
到对应项目后,通过下面命令克隆项目,并进入项目文件夹
1 | git clone https://github.com/comfyanonymous/ComfyUI.git |
二、Conda环境配置
当前版本的ComfyUI推荐使用python3.13环境,因此这里使用的是3.13,可以根据comfyUI的项目网站,找到推荐的python版本。
创建 Python 环境
1 | conda create -n comfyui python=3.13 -y |
这里使用 python --version 确认 python 版本。
安装 PyTorch
这里安装 cuda 13.0 pip版本,可以根据实际情况安装其它版本的pytorch。
1 | pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu130 |
测试:
1 | python - <<'PY' |
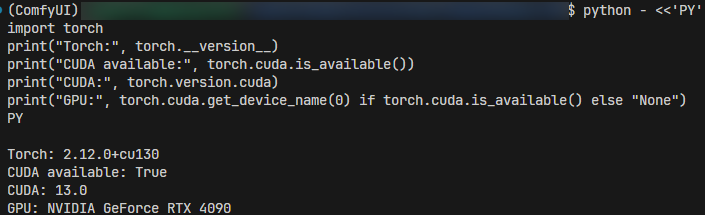
看到下面这行说明安装成功,并可以正常使用 cuda 加速
1 | CUDA available: True |
下面是我安装到这一步的截图:
安装 ComfyUI 依赖
1 | python -m pip install -r requirements.txt |
等待依赖安装后即可尝试运行,输入以下命令:
1 | python main.py |
运行成功截图如下,可以看到:
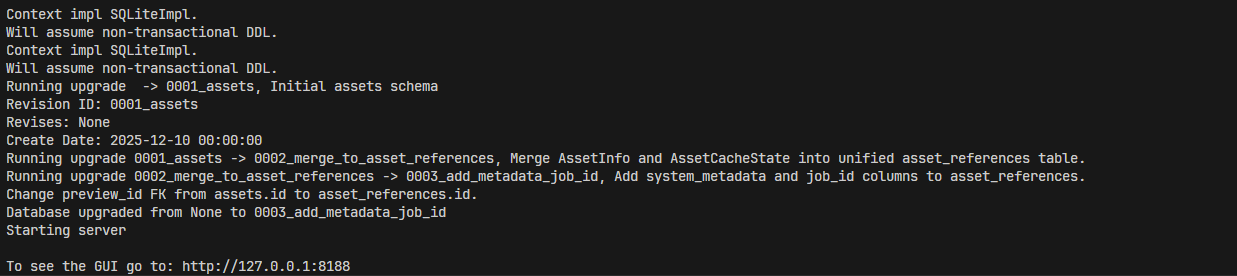
看到这个就说明,ComfyUI已经启动了,如果使用ssh连接远程服务器,可以在vscode等IDE看到出现了一个端口,选择在浏览器打开即可使用ssh隧道打开对应网页。如果没有使用vscode,仅使用ssh命令行,可以用ip:8188的方式连接。
使用Ctrl+C结束,下面安装ComfyUI Manager
安装ComfyUI Manager
ComfyUI-Manager 是 ComfyUI 生态中最核心、最推荐的必备插件。它相当于一个“应用商店”和“环境管家”,能让你通过图形化界面一键安装、更新和管理成百上千的自定义节点(Custom Nodes),彻底告别繁琐的手动 Git 克隆和依赖修复。
由于近期 ComfyUI 官方进行了架构调整,目前的安装方式主要分为以下几种情况:
新版ComfyUI(自带 Manager,需手动启用)
如果你使用的是最新版本的 ComfyUI,Manager 其实已经内置在核心代码中了,只是默认没有开启。可以通过以下步骤直接启用它:
安装管理器依赖:
1 | pip -m install -r manager_requirements.txt |
启动时添加参数:
在启动 ComfyUI 时,需要在运行命令后加上 --enable-manager 参数。例如:
1 | python main.py --enable-manager |
常规手动安装(适用于大多数版本)
如果你的版本较旧,或者习惯传统的安装方式,可以直接将其作为一个普通的自定义节点来安装:
- 打开你的 ComfyUI 文件夹,进入
ComfyUI\custom_nodes目录。 - 在此处打开终端(CMD 或 PowerShell)。
- 执行 Git 克隆命令(确保电脑已安装 Git):
git clone https://github.com/ltdrdata/ComfyUI-Manager comfyui-manager - 重启 ComfyUI,界面上方就会出现 Manager 按钮
三、下载SDXL模型
这里使用hugging face下载SD模型,国内网络环境原因,直接连接hugging face需要有学术网络访问或魔法,这里我使用了学校提供的学术网络访问下载的模型。如果你不在大学做学生或老师,也不再霍格沃兹修读魔法,可以选择hf-mirror下载,这是hugging face的社区镜像,十分完善,速度也很快。也可以访问阿里巴巴达摩院下的魔搭社区,里面也有需要下载的模型。
安装 Hugging Face CLI:
1 | pip install -U huggingface_hub |
有些模型需要登录:
1 | hf auth login |
创建模型目录:
1 | mkdir -p models/checkpoints models/vae models/loras models/controlnet models/upscale_models |
下载 SDXL Base:
1 | hf download stabilityai/stable-diffusion-xl-base-1.0 \ |
可选,下载 SDXL Refiner:
1 | hf download stabilityai/stable-diffusion-xl-refiner-1.0 \ |
可选,下载 SDXL VAE:
1 | hf download stabilityai/sdxl-vae \ |
目录大概是:
1 | <你的项目>/ComfyUI/models/ |
ComfyUI 官方文档说明模型需要放进 models 下对应类型目录,例如 checkpoint、VAE、LoRA 等。
下面为你详细拆解这三者的区别和作用:
stable-diffusion-xl-base-1.0(基础模型)
- 角色定位:“总设计师”与“构图者”。
- 核心作用:这是 SDXL 的核心主模型。它的主要任务是根据你的提示词(Prompt)来理解语义,并负责生成图片的整体构图、色彩基调以及大致的画面内容。
- 日常使用:如果你只想下载一个文件就跑 SDXL,那就是它。单独使用 Base 模型已经能生成质量很高的图片了。
**stable-diffusion-xl-refiner-1.0(精修模型)
- 角色定位:“后期修图师”与“细节狂魔”。
- 核心作用:它是一个专门用来“锦上添花”的模型。Refiner 不能凭空从文字生成图片,它必须接收 Base 模型生成的半成品(潜空间特征),然后对画面进行二次加工。它能极大地提升图片的高频细节(比如皮肤纹理、发丝、布料褶皱),让光影过渡更自然,画质更逼真。
- 日常使用:在 ComfyUI 中,通常会将它串联在 Base 模型之后。如果你觉得 Base 模型直出的图有点“肉”或者不够锐利,加上 Refiner 效果会立竿见影。
sdxl-vae(变分自编码器)
- 角色定位:“最终翻译官”与“调色盘”。
- 核心作用:AI 内部运算时使用的是人类看不懂的压缩数据(潜空间 Latent)。VAE 的作用就是充当“解码器”,把这些 AI 的内部数据翻译成我们肉眼可见的最终像素图片。
- 为什么需要它:SDXL 专用的 VAE 经过了特殊优化,能让生成的图片色彩更鲜艳饱满,对比度更好,且能有效避免画面出现灰蒙蒙、过曝或奇怪的色块伪影。如果不用它(或者用错了老版本的 VAE),生成的图片往往会严重偏色。
** 总结与类比**
为了让你更直观地理解,我们可以把生成一张图的过程比作拍电影:
- Base (基础模型) 是导演兼摄影师,负责搭好场景、找好角度,拍出电影的初版样片。
- Refiner (精修模型) 是后期特效团队,给样片做高清修复、加细节、调光影,让画面达到影院级质感。
- VAE (解码器) 是放映机/显示器,负责把处理好的数字信号完美地呈现在观众眼前,保证颜色不失真。
注意:上述区别内容由AI生成
四、运行ComfyUI
推荐启动命令
显存8G左右
1 | python main.py \ |
显存12G左右
1 | python main.py \ |
显存大于16G
1 | python main.py \ |
如果只是你自己在服务器本机使用,也可以直接:
1 | python main.py --enable-manager |
五、测试出图
运行成功后浏览器如图所示:
先跑通base模型,不用着急加Refiner
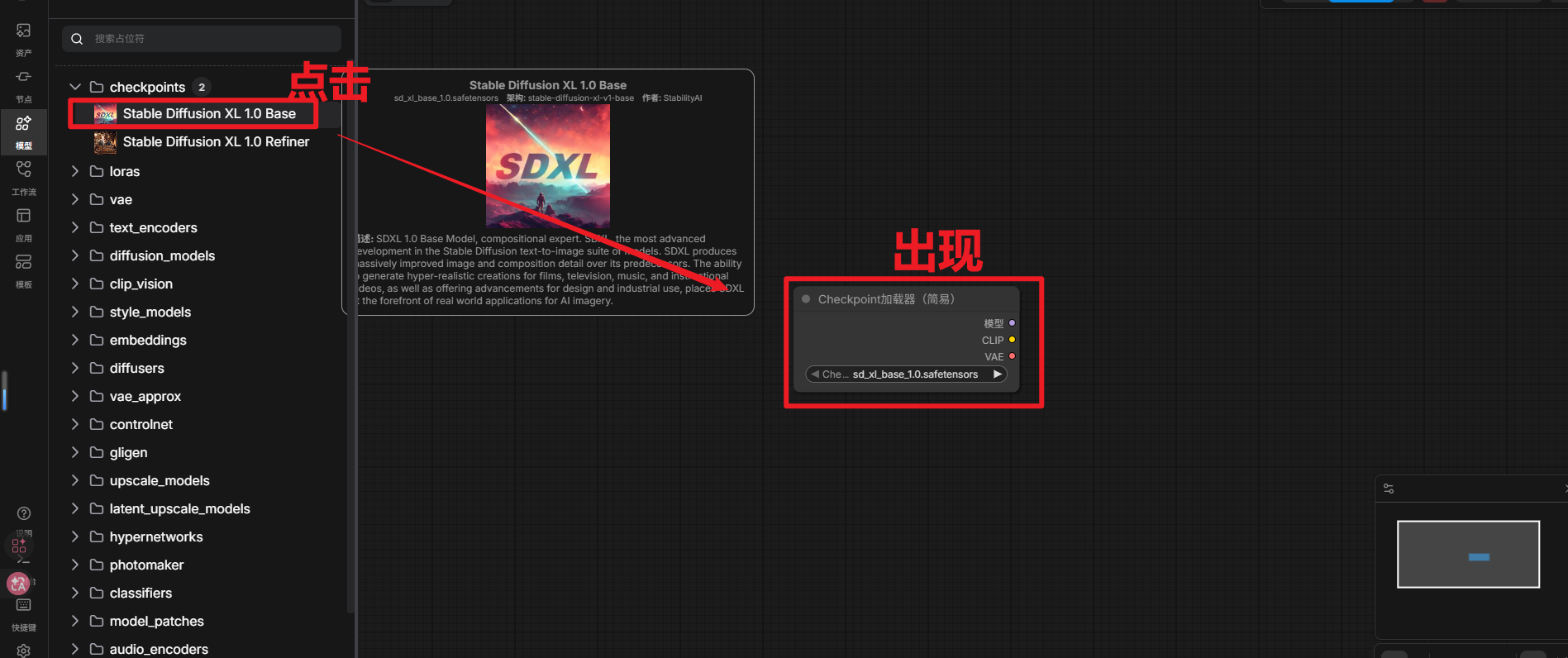
1.添加Load Checkpoint(Checkpoint加载器)节点
找到下载的模型点击可以在图形中看到:
2.添加CLIP encode(CLIP文本编码)节点
双击空白处,添加两个CLIP文本编码节点
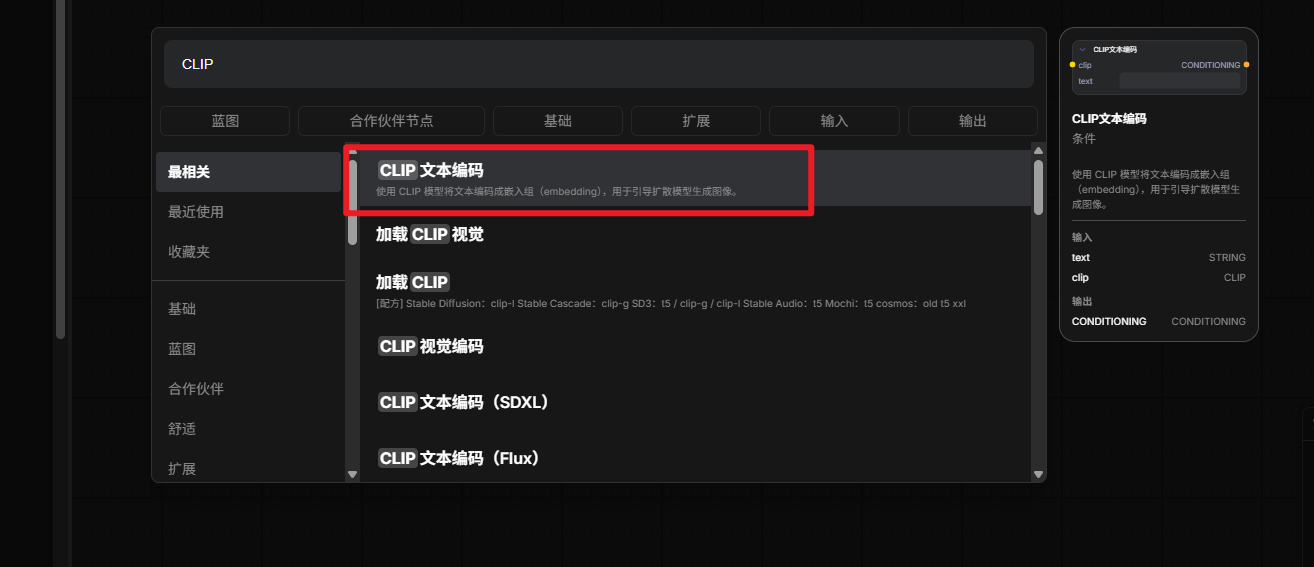
一个作为正向提示词,写:
1 | a cinematic photo of an orange cat wearing an astronaut suit, standing on Mars, Earth in the background, soft lighting, highly detailed, realistic |
另一个作为反向提示词,写:
1 | low quality, blurry, bad anatomy, distorted hands, extra fingers, watermark, text, logo |
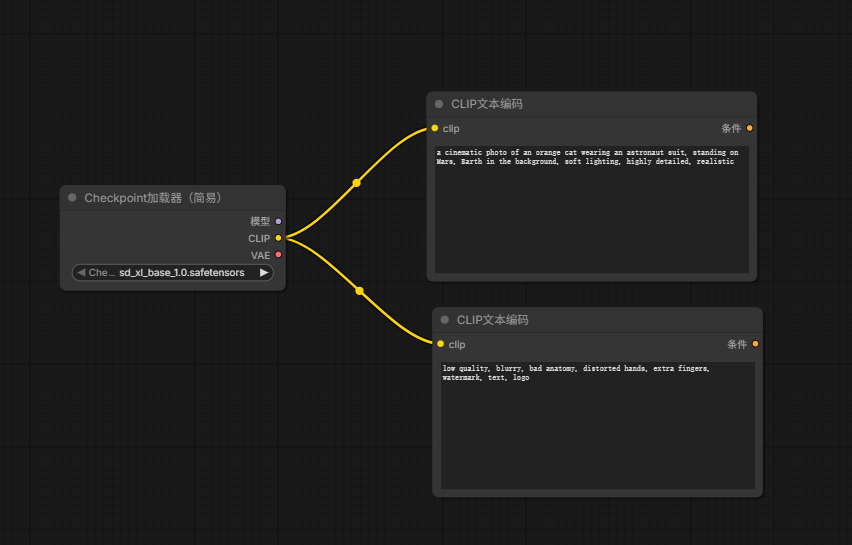
然后连接:
3.添加Empty Latent Image(空Latent图像)
添加空latent图像
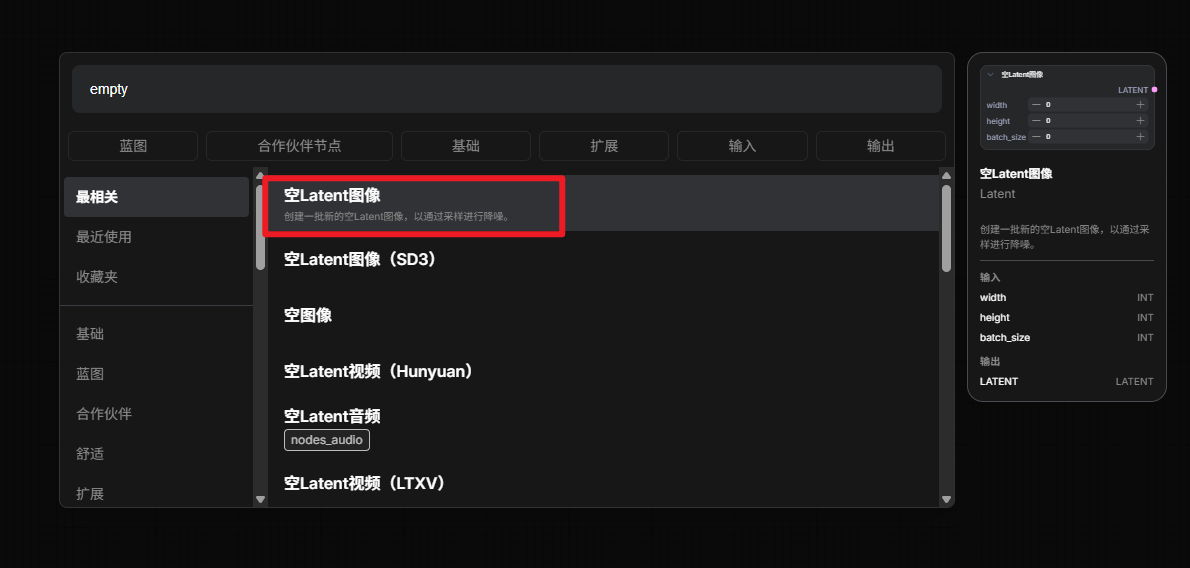
参数设置:
1 | width: 1024 |
Empty Latent Image 可以理解成设置画布尺寸,官方基础文生图教程也是用它来决定最终生成图像尺寸。
4.添加KSampler(K采样器)
K采样器是调用模型的重要节点。
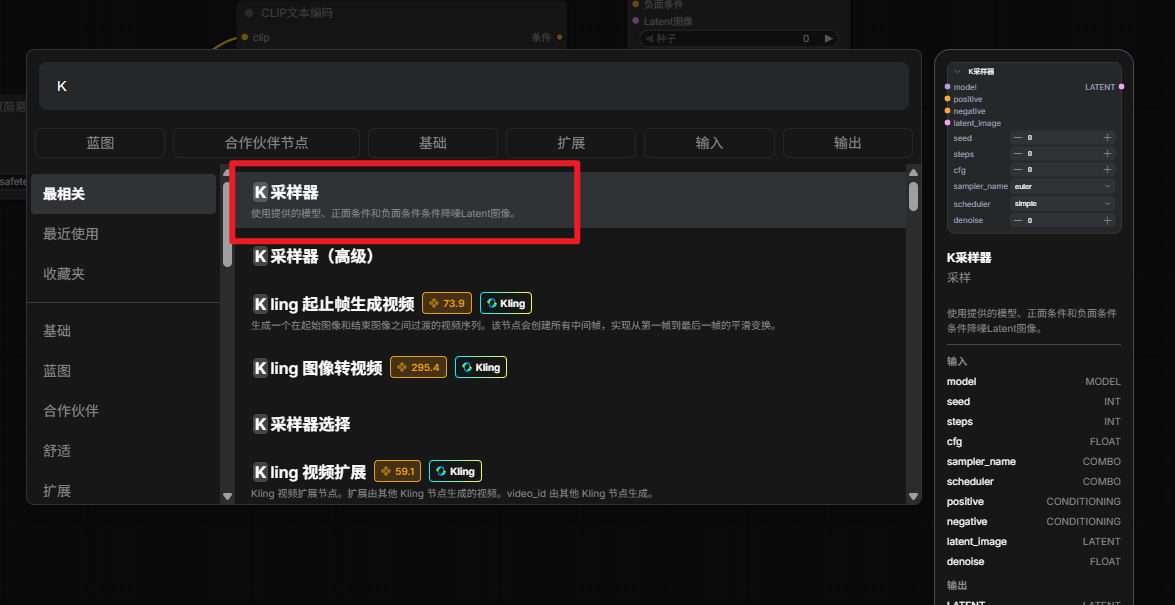
参数先这样:
1 | seed: 随便,或者点 randomize |
参数中,cfg表示,模型有多听话,sampler_name是制定采样器,该参数决定了是哪个“画师”来画这幅画。选dpmpp_2m效果旧不错。
然后连接:
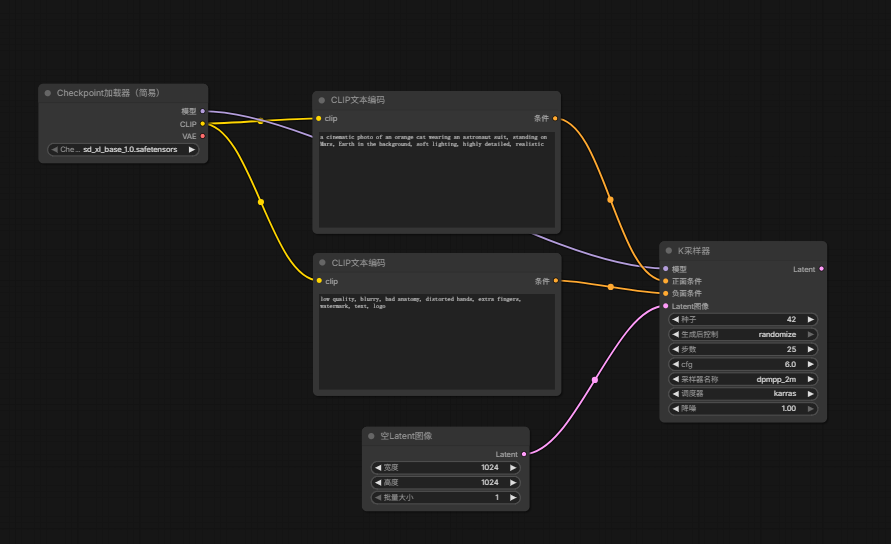
5.添加VAE Decode
添加VAE decode节点和load VAE节点
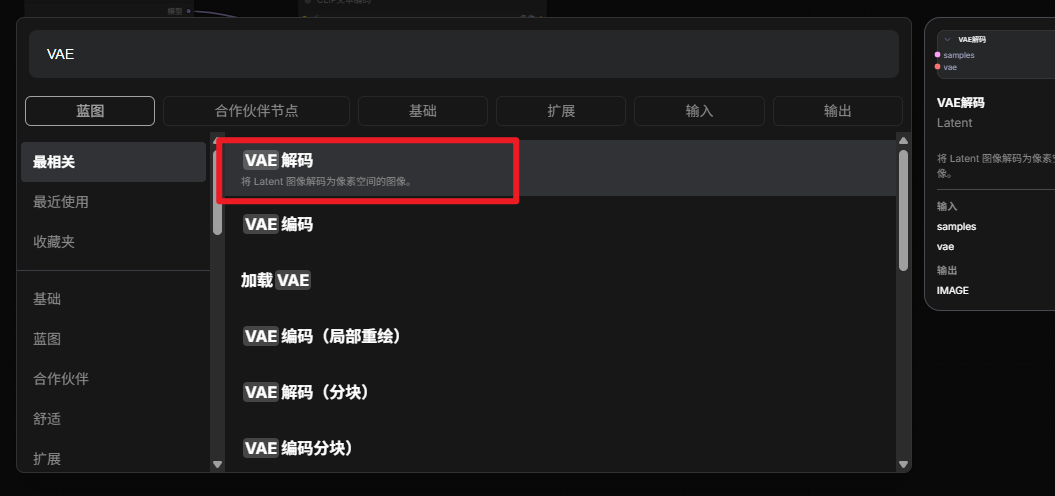
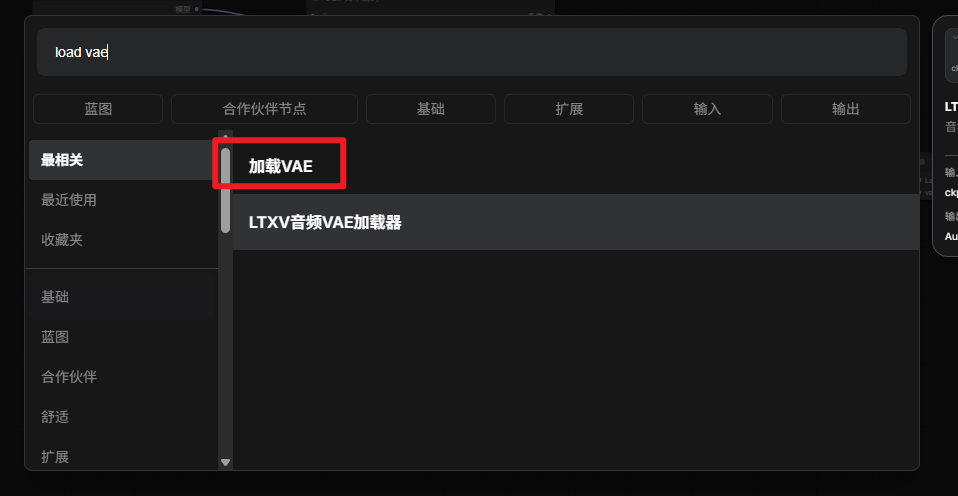
连接如下:
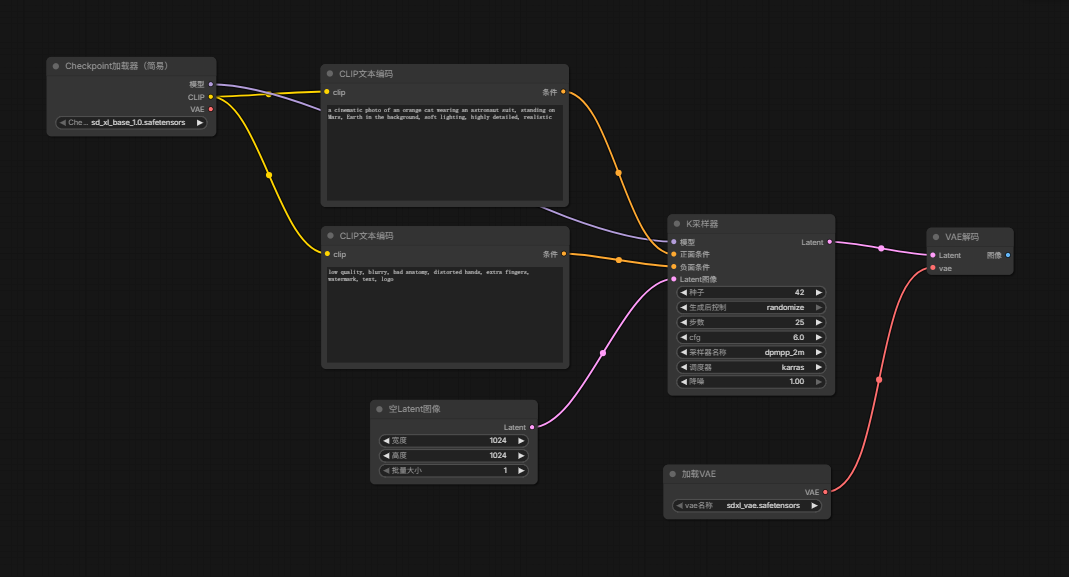
添加save image
最终节点连接如下图
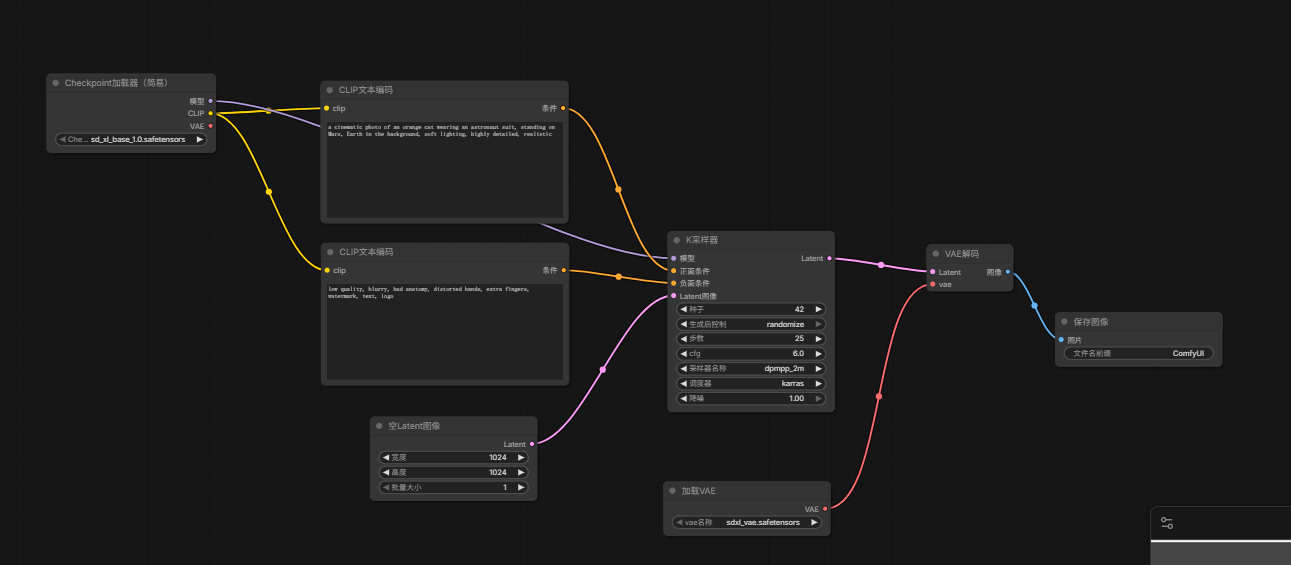
6.运行
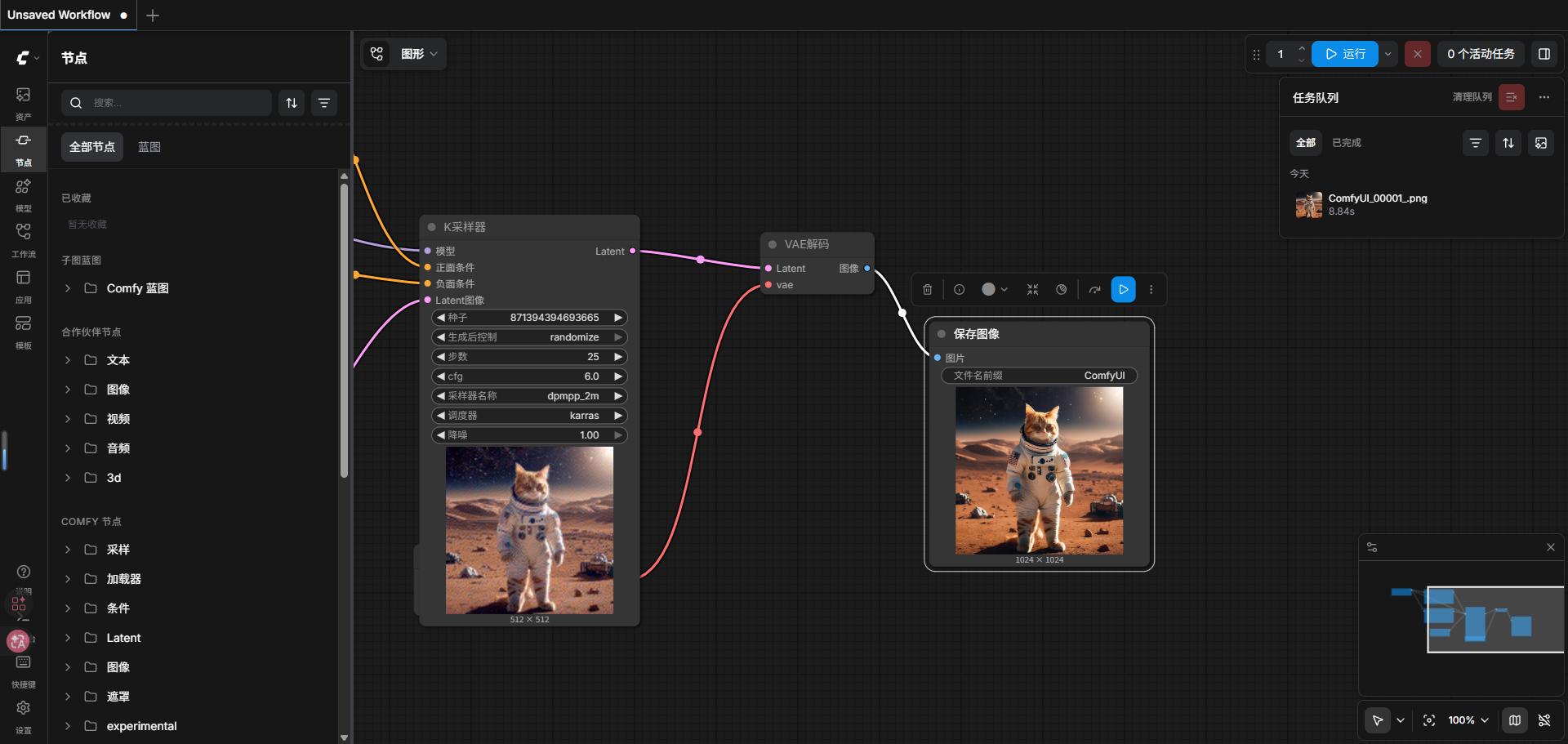
最后点击右上角的运行即可跑通流程,如图为画好图片后的样式:
加上Refiner
保留之前的全部节点,然后进行下面操作
1.修改基础K Samper(K采样器)
参数如下
1 | steps: 25 |
注意,这里denoise为0.8,不要为1,因为要留一些空间给refiner细化
2.添加一个Load Checkpoint(Checkpoint加载器)
双击搜索添加后选择refiner模型
3.给refiner添加两个CLIP Text Encode(CLIP文本编码)
一个正向,一个反向。
Refiner 正向可以先复制 Base 的正向提示词:
1 | a cinematic photo of an orange cat wearing an astronaut suit, standing on Mars, Earth in the background, soft lighting, highly detailed, realistic |
Refiner 反向也复制:
1 | low quality, blurry, bad anatomy, distorted hands, extra fingers, watermark, text, logo |
都连接到refiner的CLIP上。
4.添加第二个K Sampler(K采样器)
这个作为:Refiner K Sampler。
参数设置:
1 | steps: 20 |
这里 denoise 不要太高,refiner 是精修,不是重画。
5.连接refiner K Sampler
如图所示,将正负面条件、模型连接,基础K采样器输出的Latent图像连接到refiner的K采样器上。
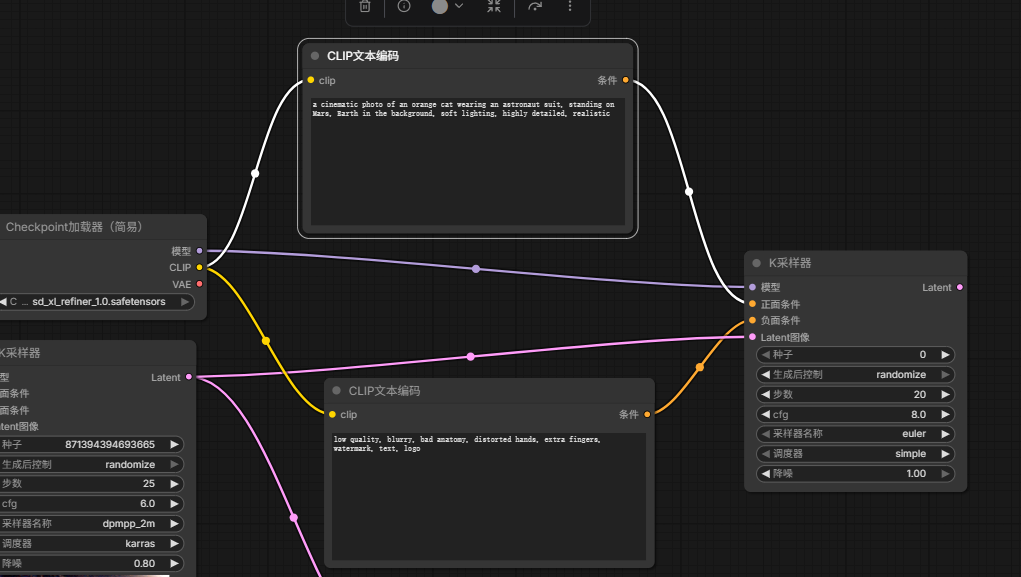
6.修改VAE输出
最后把VAE decode 改接refine的输出。最终的节点整理后如图所示。
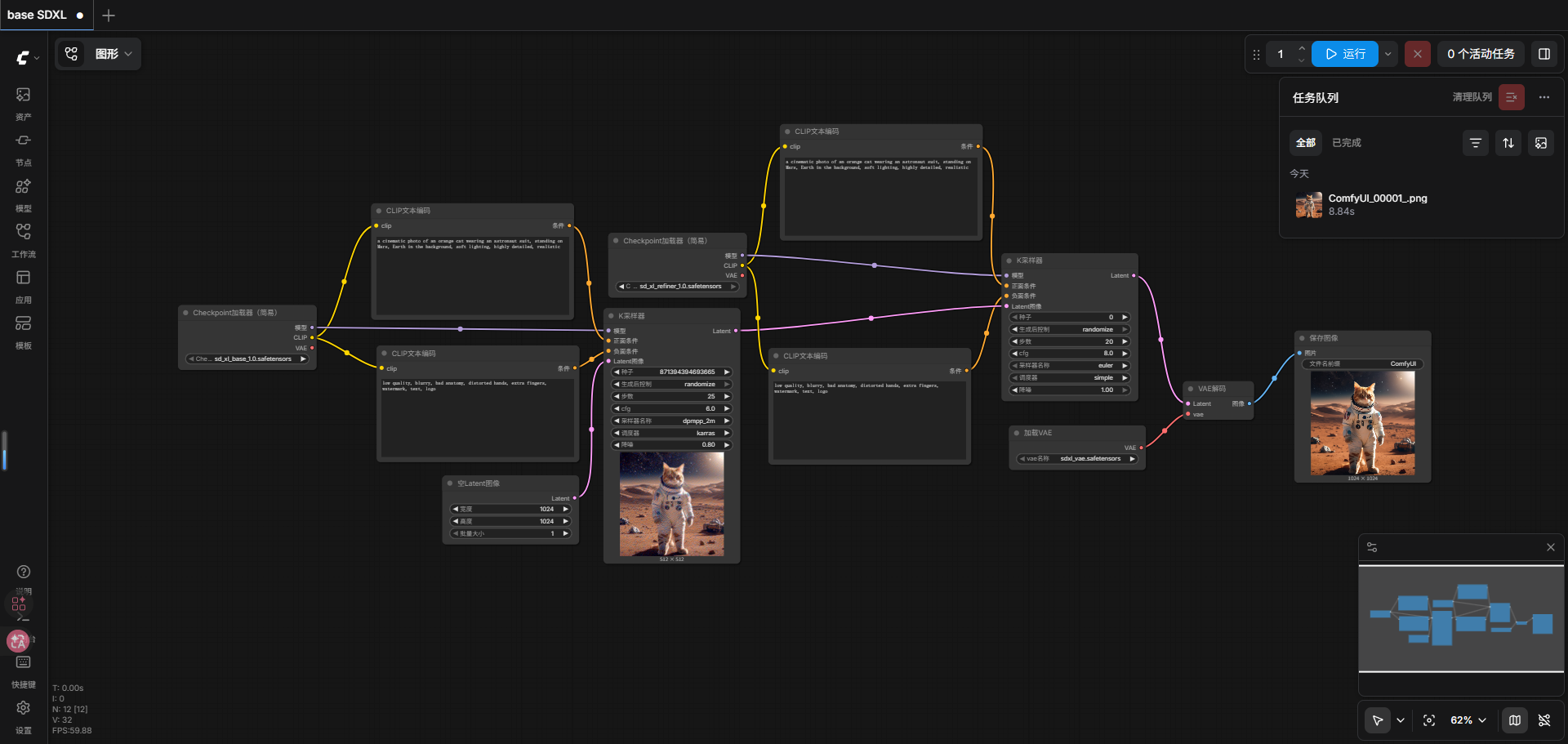
7.运行
运行后查看输出如图,多次测试后终于出了正常的图像。
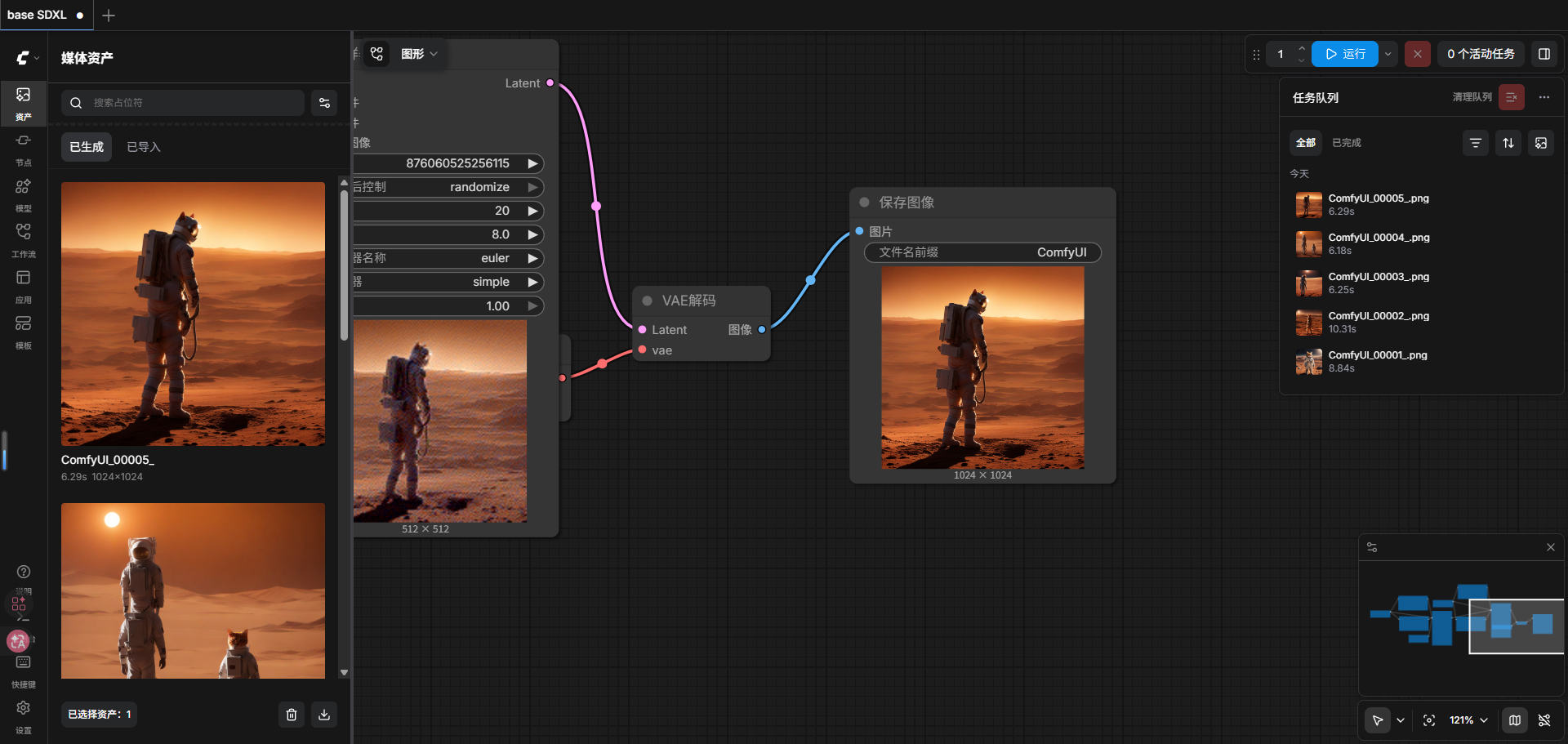
六、下一步学习顺序
建议顺序是:
1 | 1. 文生图 txt2img |